新刊情報をPythonで一気に自動抽出して格納する技
本ページにはプロモーションが
含まれていることがあります

読書お好きな皆さん、新刊情報をいつもどのようにチェックしていますか?情報が多すぎて、本当に読みたいものを見逃していないか心配になったりしませんか?
わが家では、私(ヤン)も夫(S氏)も大の読書好きです。読み切れないくらいの本を買って帰るとなんともいえぬ「ハイな気分」になります😸😀。
私は小説や社会学を読むのが多いです(仕事関連以外では)。夫は小説だけは読まないけど、それ以外は本当にジャンルが広すぎますね。
夫が買ってきて読んだ本は(堅い政治経済のを除いて)、だいたい私がその後もらって読みます。「あの人が知っていることを私が知らないのは許せない」的な複雑な感情…?
そこで、Pythonの自動化術を活用して、以下のことを可能にしました。
- 楽天ブックスサイトから、該当月の新刊を一気に取得してくる
- 重複ものや興味範囲外の書籍を排除
- 刊行日、タイトル、著者、出版社、メディアの情報をファイルに出力
この出力結果を手にして書店に走っていき、ワクワクと棚を満遍なくチェックできますね!
これは単なる一例ですが、「Pythonでこんなことが簡単にできるのか!」を実感してみてください。
さて、コードを実際見てみます。皆さんも記事と一緒に試しましょう❗️❣️
今回は動作をstep-by-stepで確認できるJupyter Notebook で記述し、Anaconda上で動かしています。最後にGoogleColab上で動かしたい方のためのメモも添えてありますので、さほど変わりませんよ。
AI・データサイエンス、機械学習の
実践力を高めたい方へ
- プログラミングを0から学びたい
- データサイエンティスト、データアナリストを目指したい
- AIエンジニア、大規模言語モデル(LLM)エンジニアを目指したい
AI人材コースを
無料体験してみませんか?

フリープラン登録で無料で120以上の教材を学び放題!
生成AIを使うだけでなくAIの本質を理解し課題解決力を習得!
重要箇所のハイライトと進捗の可視化で効率的な学習サポート!
1分で簡単!無料!
▶アカウント作成して無料体験する
30時間以上の動画講座が見放題!
追加購入不要!これだけで学習できるカリキュラム
(質問制度や添削プラン等)充実したサポート体制!
▶AI人材コースを見る
目次
初期準備
Jupter Notebook でドキュメントを作成する際に、後から自分または他社が見てわかるように「マークダウン」機能を使ってヘッダーやコメントを入れていきましょう。データ処理やデータ分析の流れを頭の中で整理しやすくもなりますよ!
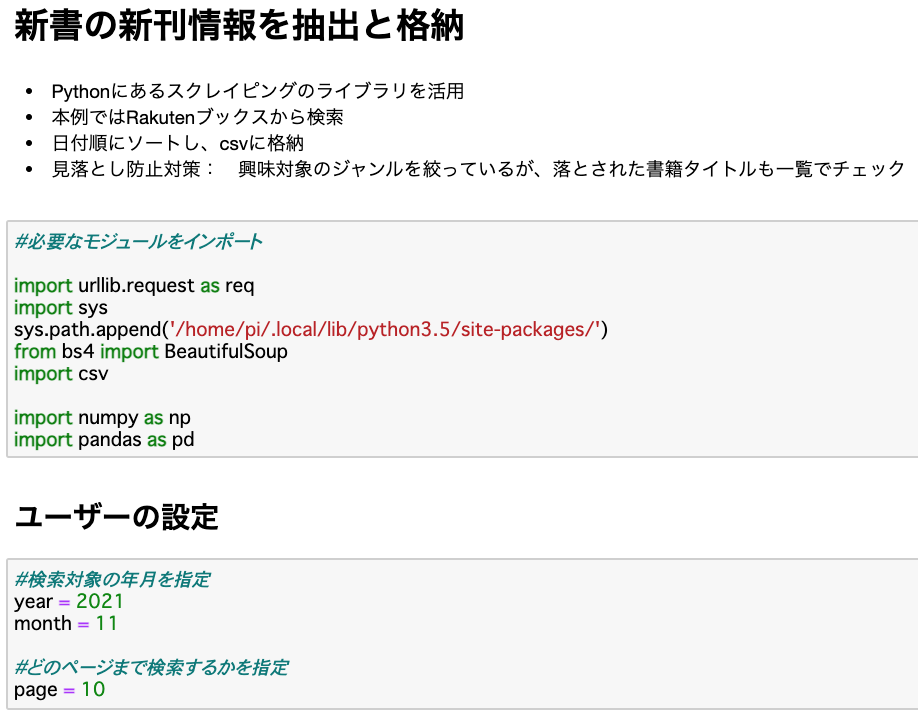
ここでは、スクレイピングがデータ整形に必要なライブラリやモジュールをimport(コードの中で使える状態に)します。
つぎに、何年何月をデータ検索と収集の対象とするかを「変数」として指定します。
ウェブ・スクレイピングの実行
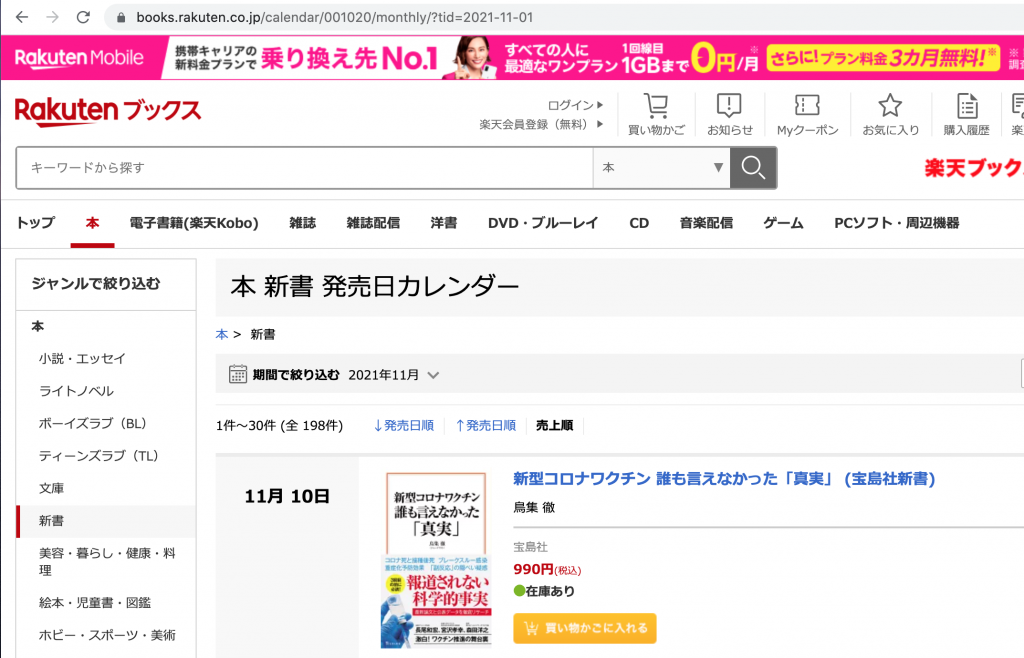
今回は楽天ブックスのページからデータを集めます。そして「新書」のみ見ることにします。
スクレイピングのインプットとするURLの構造をよく観察しましょう。
基本となる https://books.rakuten.co.jp/calendar/001020/monthly/?tid= の後に、year と month と day の情報が決められた形式で入ります。実はdayの部分はここではあまり重要ではなく、コードの中では毎月の初日を基準にすると決めたので、コードの中では01に固定しています。
URLの中に見える001020 の部分は「新章」カテゴリに対応します。ユーザー設定の部分でここも流動的な変数にできますね。
ページを「次へ」と進むとさらに終端にページの情報もURLに付け加えられます。
(注)クロール・スクレイプする先のサイトの利用規約を事前に確認してください(商用禁止やアクセス制限など)。今回は個人の趣味のため。
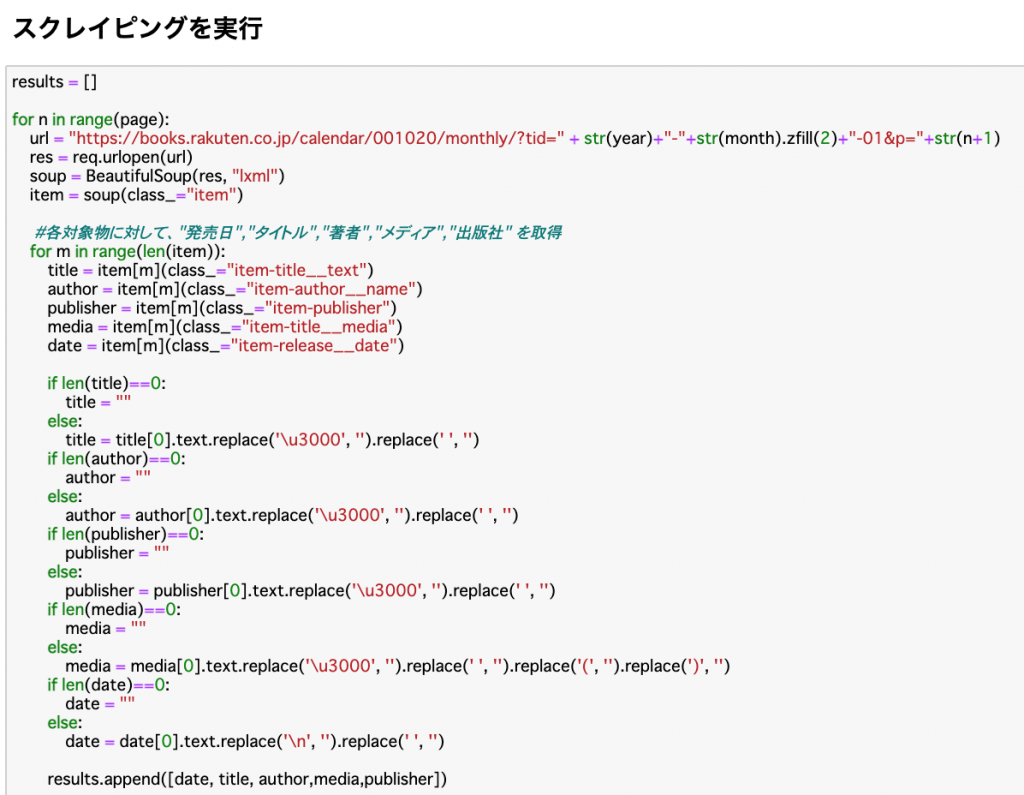
上で設定したユーザー変数 year, month , page を使って、スクレイピング実行のコードを表現します。url の部分には文字列の連結を用いて、yearとmonthを入れています。変数n はページのそれぞれを代表しています(1ページ目からpageで指定したページまで、ここでは10)。
Beautiful Soup とは、HTML などからお目当てのデータを抽出するためのライブラリです。公式ドキュメントによると、 HTML や XML のパーサーを「ラップ」(パッケージ化)して扱いやすくしているライブラリと解釈できます。一般的には、HTML の取得は requests を使い、HTML の「パース処理」(異なる種類の情報を含む部分にカテゴリ化するイメージ)を Beautiful Soup で行います。
この部分のコードでは、”Soup”の中の、各対象物(見つかった新書オブジェクト)に対して、”発売日”,”タイトル”,”著者”,”メディア”,”出版社” の情報を専用のタグを使って取ってきます。
この部分では。Pythonが得意とする繰り返し処理、と条件分岐をフルに活用していますね。また表示する際に、HTML特有の記述文字を読みやすいものに、replace() 関数で置き換えています。
以上の取得、整理した項目たちを results という名称の2次元のリスト(Python特有の配列)に一旦格納します。
抽出した結果であるresults の形式を目視で確認します。ここまで問題なさそうですね。
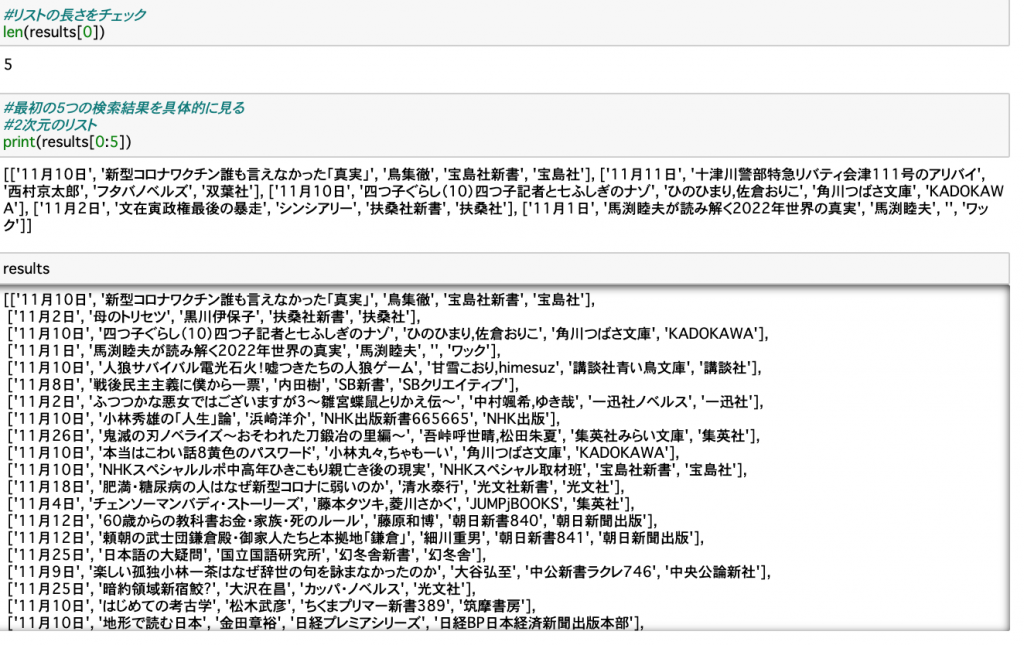
興味のある新書に絞る
ここでは、とりあえず夫がよく読むジャンル(私より広い(笑))を思いつく限り書き出してみました。もちろんこのコードを書く皆さんはご自身の好きなもので置き換えてくださいね。

たまに「いつも読んでいるジャンルには分類されないけど、面白そうな本があるので、新規開拓しよう」はありますよね。
そこで、以下の部分では、上記の「興味範囲」に該当するものを一旦 accepted_results という新規のリストに入れながらも、落選したものrejected_mediaやrejected_titlesもチェックします。
accepted_results を日付順にソートします。



これらを実行すると、今回指定した「興味範囲」から外れたものを念のためにチェックできます。
データを整形(重複の排除など)
常に理由を明らかにできるわけではないけれども、スクレイピングした結果に重複行ができることができます(初期段階で出力データを確認すると気づきます)。そこで、Pandasパッケージの機能を使って重複を取り除きます。
リストのデータを一度Numpy配列(もっとデータ量が大きい時は高速化に寄与)にしてから、PandasのDataFrameに入れます。これでユニークな列に絞りやすくなります。
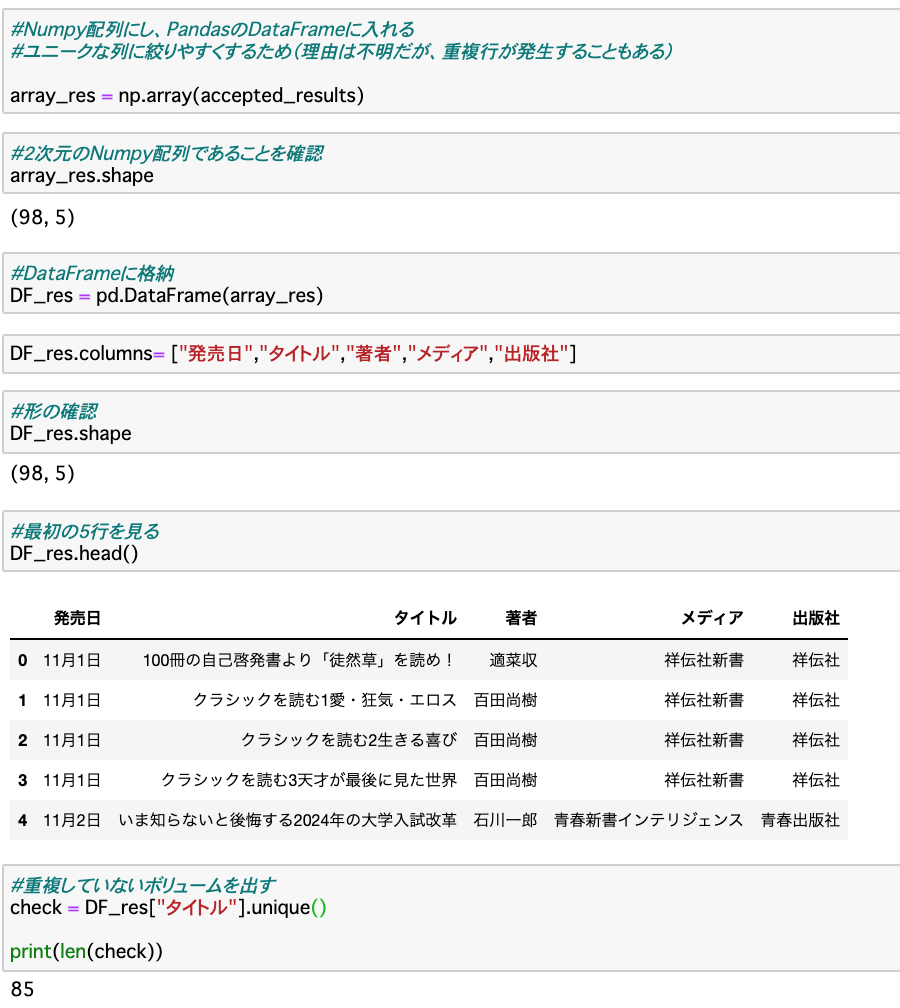
DF_res と読んでいるDataFrameに対して、duplicated() 関数を使うと重複されているものが分かります。
また、drop_duplicated() 関数を使うことで、重複をdrop(落す)したデータのみ残したデータを新しいDataFrame DF_res_new として格納します。
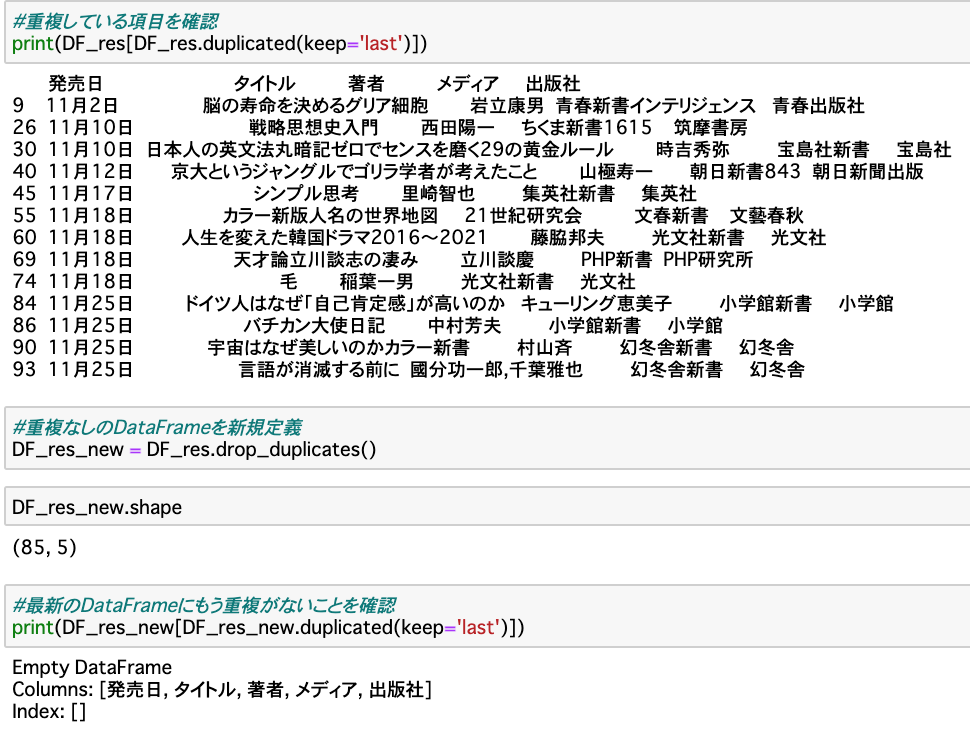
もう一度全体の様子を確認。欲しい列が日にち順で並んでいて、かつ重複がなくなったことが最後に表示されている件数からも分かりますね。
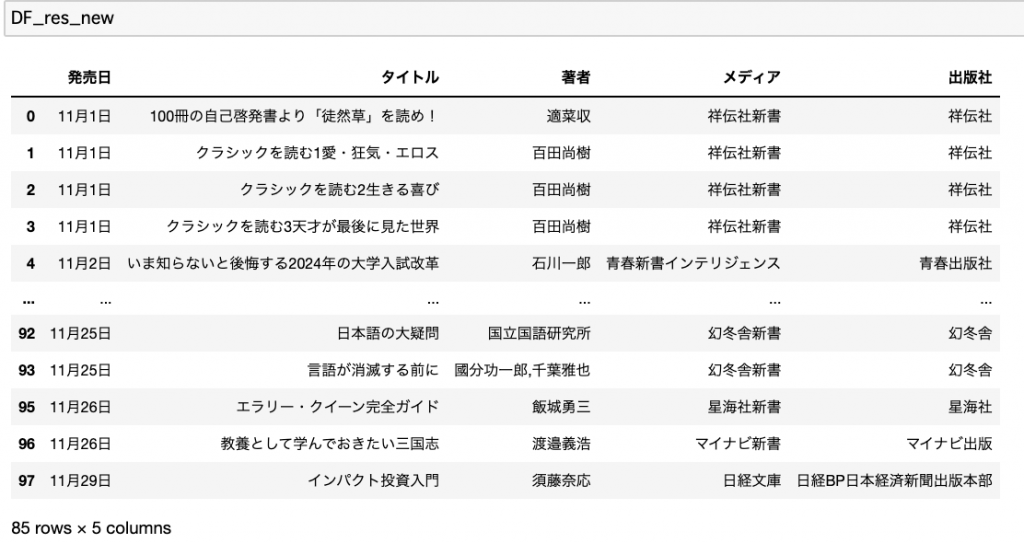
抽出データの格納・出力
Pandasの to_csv() 関数を使って、DataFrameを直接CSVとして書き出します。
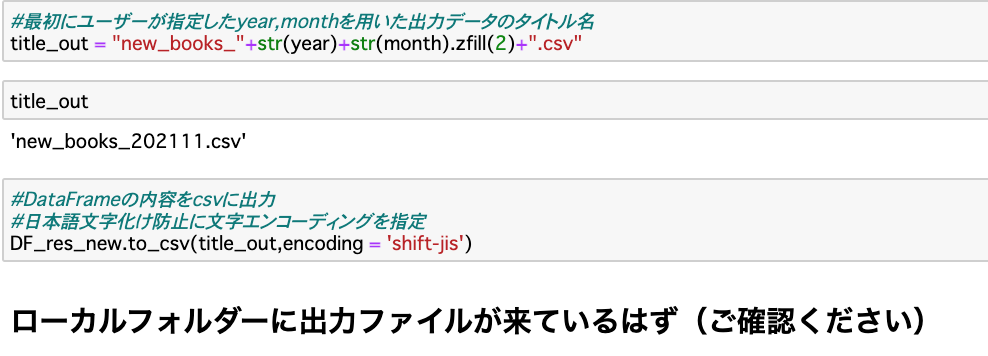
皆さんに宿題
以下は、得られたcsvファイルの冒頭部分です。
ここで、さらなる挑戦として、日付だけではなく、同じ日付の中で出版社ごとにソートすることです。ぜひチャレンジしてみてください!
なぜこのことをしたいかというと、書店は多くの場合、出版社ごとに書籍が置いてあります。こうすると新書を探しやすくなります!

皆さんも、スクレイピングの技術やPythonを使って、身の回りで達成したいことを同様にやってみてはいかがですか?
今回活躍した技術をマスターできるお手軽講座
AnacondaやJupyterNotebook の使い方から、Pythonの数値的変数、文字列変数の処理、関数、までを超初心者の方でも楽々学べる講座として↓をお勧めします!
また、今回たくさん使った、繰り返し処理(ループ処理)や条件分岐といったPythonによるデータ処理の基本は↓でマスターできます!
さらに、NumPyやPandasを用いたさらに高度なデータ前処理やデータ分析は↓の3つ目でたっぷり演習できます。
(メモ)GoogleColab上でも動かせる!

AI・データサイエンス、機械学習の
実践力を高めたい方へ
- プログラミングを0から学びたい
- データサイエンティスト、データアナリストを目指したい
- AIエンジニア、大規模言語モデル(LLM)エンジニアを目指したい
AI人材コースを
無料体験してみませんか?
フリープラン登録で無料で120以上の教材を学び放題!
生成AIを使うだけでなくAIの本質を理解し課題解決力を習得!
重要箇所のハイライトと進捗の可視化で効率的な学習サポート!
1分で簡単!無料!
▶アカウント作成して無料体験する
30時間以上の動画講座が見放題!
追加購入不要!これだけで学習できるカリキュラム
(質問制度や添削プラン等)充実したサポート体制!
▶AI人材コースを見る

この記事の著者 ヤン ジャクリン
2015年 東京大学大学院 理学系研究科物理学専攻 修了(理学博士)
2015年 高エネルギー加速器研究機構 素粒子原子核研究所(博士研究員)
2017年 株式会社GRI(現職) 講師 兼 分析官
2019年 Tableau Desktop Certified Associate 資格取得
・英検1級
・TOEFL IBT試験満点
北京生まれ、米国東海岸出身(米国籍)、小学高学年より茨城県育ち。
万物の質量の源となるヒッグス粒子の性質を解明し、加速器実験による新粒子発見に関する研究を行い、国際・国内学会発表20件以上、査読論文5件以上。
10年以上に渡り、幅広い年齢層の学習指導を学習塾や大学などで実施(5科目、英会話、受験指導、素粒子物理など)。
現在は、株式会社GRIにて、データ分析官(データ前処理、可視化分析、マーケティング施策の分析 他)
公開講座および法人研修を多数開設。



