機械学習とは?教師ありなし・強化学習などの種類も簡単にわかりやすく解説!
本ページにはプロモーションが
含まれていることがあります

今日では日常の中で人工知能(AI)やデータサイエンスなどのブームワードを常に耳にするようになりました。
この記事では、AIと深く関連する概念である「機械学習」について本質を理解しましょう。
AI・データサイエンス、機械学習の
実践力を高めたい方へ
- プログラミングを0から学びたい
- データサイエンティスト、データアナリストを目指したい
- AIエンジニア、大規模言語モデル(LLM)エンジニアを目指したい
AI人材コースを
無料体験してみませんか?

フリープラン登録で無料で120以上の教材を学び放題!
生成AIを使うだけでなくAIの本質を理解し課題解決力を習得!
重要箇所のハイライトと進捗の可視化で効率的な学習サポート!
1分で簡単!無料!
▶アカウント作成して無料体験する
30時間以上の動画講座が見放題!
追加購入不要!これだけで学習できるカリキュラム
(質問制度や添削プラン等)充実したサポート体制!
▶AI人材コースを見る
目次
機械学習とは?
機械学習を最初に定義を与えたのは、世界初の学習型プログラムを開発した米国の計算機科学者のアーサー・サミュエル(Author Samuel)です。
サミュエル氏による機械学習の定義は以下です。
“明示的にプログラムしなくても学習する能力をコンピュータに与える研究分野”
「明示的にプログラムしなくても」の部分が定義の中で一番重要です。これはどういうことだと思いますか?(*)
機械学習は人工知能(AI)の中の一つの手法です。
図1のように、AIは、ルールベースの手法と機械学習の手法に分けることができます。よって、機械学習はAIの部分集合という考え方ができます。

ルールベース
人間があらかじめ設定した動作ルールに従って行動する仕組みのことです。
ある条件Aの下で、Bという入力データが入ってきたら、Cという出力を出しなさい、のような一連の命令が事前に決められており、AIはそれに忠実に従って出力を出すだけです。
機械学習
大量な学習データをもとに、汎用的なルールやパターンを、学習というプロセスを介して導き出す手法です。
ここでは「学習データを用いていること」と「学習が行われること」がポイントです。
同じくAIの1つの分野であるルールベースとは異なり、機械学習では、大量な学習データをもとに、法則やパターンを自動的に見出すという意味で、人間が明示的にルールをいちいちプログラムしてあげなくてよいのです。これは(*)への答えです。
機械学習は効率的にコンピュータが学習を行うことを可能にしたAIの技術であり、今では様々な分野で応用されています。
コンピュータに「人間らしい」認識や判断の能力を発揮させるためには、振る舞いの基準を定める必要があります。
例えば、年収によってクレジットカードの審査が通るかどうかを判定する機械学習プログラムでは、「年齢の最低値」や「年収の最低値」などの判断軸や閾値がその基準にあたります。
ルールベース手法では、基準の閾値を人間が指定する必要があるが、機械学習ではそれを自動的に見出すことができます。
ここでいう「基準」のことを計算機科学では「パラメータ」と呼ぶことがあります。パラメータの最適値を見出すことがまさに機械学習における「学習」です。
2000年に入ってから、インターネットの普及により、データが流通・収集・蓄積しやすくなりました。
いわゆるビッグデータの時代となりました。膨大な量のデータ(=ビッグデータ)を学習に使用できるようになることは、汎用的なパターン・法則を見つけることにとって都合が良いです。(注:ビッグデータの時代においても、必ずしも全ての機械学習がビッグデータを必要とするとは限りません。)
なお、機械学習のプログラムを書く際に、Pythonが用いられていることが多いことも知っておきましょう。
機械学習とAIの違い
AIとは、「Artificial Intelligence(アーティフィシャル・インテリジェンス)」の略で、人工知能とも呼ばれています。
AIは「特化型人工知能」と「凡用人工知能」の2つに分けることができます。
「特化型人工知能」は、ひとつの作業に特化したAIのことで、代表的な例では画像認識や音声認識などが挙げられます。
また、「凡用人工知能」は複数の作業を行うAIのことで、指示された情報をもとに自ら考えそれを応用することができます。
AIの領域のひとつとして機械学習があり、機械学習の技術を含んでいるものがAIとなります。
機械学習とディープラーニングの違い
機械学習と合わせて、もう1つよく耳にする用語「ディープラーニング(深層学習)」はどんな技術でしょうか?
機械学習には数多くの具体的な手法があり、用途によって使い分けます。
ディープラーニングは機械学習の手法の1つです。
図2はAIと機械学習とディープラーニングの関係性を表しています。

機械学習はデータからパターンや法則を自動的に見出せるように学習を行う手法の総称です。
従来型の機械学習を活用する上、特徴量の準備が大きな労力を必要とします。
特徴量とは「データのどの部分に着目して学習すれば良いのか」つまり予測の手がかりとなる要素です。
それに対して、ディープラーニングでは、精度の高い結果を導くために必要な情報(特徴量)をデータから自ら抽出することができて、このポイントが従来の機械学習手法との主な違いです。
機械学習の仕組み
ここで、次の質問について考えてみてください。
理想的な機械学習モデルはどんなものでしょうか?
前半では、機械学習とは人工知能の一分野であること、そして学習データから汎用的なルールやパターンを、学習というプロセスを介して導き出す手法であることを学びました。
学習のプロセスが完了した機械学習モデルを「学習済みモデル」と呼びます。
理想的な学習済みモデルの場合、新しいデータ、答えが未知のデータに対する予測に適用した際に、満足できる予測精度をアウトプットできることです。
この「汎用的な性能」のことを「汎化性能」とも呼びます。
次に、機械学習における「学習」と「予測」とはどういうことなのかを具体的に見ていきましょう。
機械学習では、①コンピュータが入力データを受け取り、モデルを学習(訓練)させます。
その後、②学習済みモデルを使って計算結果を出力します。
①「学習」と②「予測」の様子はそれぞれ図3と図4に現れています。

図3と図4を、簡単のために機械学習の中の最も広く使われる「教師あり機械学習」を使って説明します。
教師あり学習では、特徴量(学習データの特徴を表す変数 = 予測の手掛かり)と正解データ(教師ラベルとも呼ぶ)の2点セットをコンピュータに入力します。
コンピュータの中では、特徴量と正解を関連づける法則を探るように計算を回します。
結果として「このような特徴の組み合わせを持つ時はこのような出力を出すのが正解だ」のようなパターンを発見します。
このパターンを習得済みのシステムが「学習済みモデル」です。
学習済みモデルでは、ある未知のデータが入力されると、獲得した法則に基づいて適切な意思決定を支援するための答えを出力できます。
まさに人工の脳のイメージです。
一般的にはモデルを社会やビジネスに実装する前に、テストデータなどを用いてモデルの精度を検証する必要があります。
精度が不足している場合は、データ収集の方法、学習データの構成、モデルの種類や詳細設定などを修正する必要があります。
試行錯誤を繰り返して行く中で、自信をもって「汎用的」言えるモデルに辿り着きます。
機械学習の種類とやり方
機械学習にはいくつかの分野があります。
基本的には「教師あり学習」、「教師なし学習」、「強化学習」の3種類です。
それに加えてもう1つ、教師あり学習と教師なし学習の間の存在である「半教師あり学習」もあります。
以下ではそれぞれの分野のアプローチについて説明します。
ここで使う「正解ラベル」は出力データの模範となるデータのことであり、「正解データ」、「教師データ」や「教師ラベル」など、呼び方は様々です。
① 教師あり学習
- 判断基準となるデータ(正解)と特徴量が紐づいた形の学習データを用いてモデルを学習します。
- 正解と特徴量の間の関係性/パターンを見出し、予測値を正解に近づけることを目標に学習を行うアプローチです。
- 具体的に行う予測タスクは「分類問題」と「回帰問題」に分けることができます。
- 機械学習の全分野の中で、最も仕組みが解釈しやすく、業務上汎用的に利用されています。
「分類問題」は各データが所属するカテゴリを推定するタスクです。
つまり予測変数が「所属カテゴリ」です。
例として、
- 動物の画像を入力データとし、猫か犬かを識別する
- 着信メールがスパムメールか正常メールかを判断する
などが挙げられます。
「回帰問題」は、連続値を予測するタスクです。
例として、
- 過去の売上げから、将来の売上を予測する(需要予測)
- 物件条件から家賃を予測する
が挙げられます。
これらは一度に一つの予測値を出力するので「シングル出力回帰」と呼びます。
一方で、感情分析(顔画像や文章を入力として複数種類の感情スコアを出力する)のような「マルチ出力回帰」もあります。
② 教師なし学習
- 学習データには正解ラベルがついておらず、特徴量のみです。
- 狙いは、学習データ(特徴量)そのものが持つ構造を見つけ出すことです。
教師なし学習が行うタスクは主に2つあります。「クラスタリング」と「次元削減」です。
「クラスタリング」とは、データを幾つかのクラスタに分けることで、データの構造を浮かび上がらせる手法であり、K-means法が代表的なアルゴリズムです。
「次元削減」は重要な情報を際立たせるために、データを低い次元に圧縮する手法であり、主成分分析が代表的です。
図5は、教師なし学習をEC(Electric Commerce)のデータに適用し、「どんな顧客層があるのか」を認識することを目的とした分析「顧客セグメンテーション」の模式図です。
この例では、3種類の顧客が存在することが推測されたため、各種類に最適化した販促施策を打ち出せるようになります。

③ 強化学習
強化学習とは、ある環境の中で、プレイヤーのような「エージェント」が最大の「報酬」を得られるように、最適な行動を学習する手法です。
これまではゲームの世界で活躍してきました。最近では、ロボットの制御や自動運転などにも応用され始めています。
④半教師あり学習の方法
半教師あり学習は、教師あり学習と教師なし学習を組み合わせた手法です。
学習データとして、正解ラベルがついているデータとついていないデータの両方を使います。
一部のデータにのみに正解ラベルを付与されています。
それらを用いて残りの正解ラベル無しのデータに対し事前予測を実施します。
最後に全てのデータを統合します。
通常は学習データの大半には正解がついていないです。
モデル学習のためのデータを取得したり、正解ラベルをつけたりするのはコストがかかります。
正解ラベル付きのデータを十分に用意できない場合に半教師あり学習が活躍できる可能性はあります。
一方で、半教師あり学習は、教師あり学習に比べて精度が低いことが多いです。
正解ラベルをつける際に偏りが多少生じる可能性があり、これが精度低下の原因になりえます。
更に予測したラベルの正確さを確認することができないので、信頼性の面においても教師あり学習には及びません。
従って、正解ラベル付き学習データを用意する余裕がある場合は教師あり学習の方がおすすめと言えます。
機械学習が使われている身近な例
今では、様々な業界においては、機械学習のビジネス・ニーズが急上昇しています。
機械学習が単なる学問にとどまらず、しっかりと社会実装されてきた結果、日常生活が大きく変わってきました。
私たちは現在、日々機械学習の技術に基づいたアプリケーションやサービスから恩恵を受けています。
ここでは一旦、機械学習は具体的に身の回りでどんなところで使われているのかについて考えてみましょう。
《機械学習の活用例1》需要予測
需要予測とは、過去のデータを用いてパターンを見出し、それに基づいて将来の状態を予測するタスクです。具体例として以下が挙げられます。
- 今月までの購買履歴データを用いて来月の売上高を予測する
- 売上数を予測することによって、在庫状況の最適化を図る
- 過去の株価の変動のパターンから将来の株価を予測する
《機械学習の活用例2》分類タスク
分類タスクでは、各データの特徴に基づいてどのカテゴリに所属しているかを判断します。
具体例として以下が挙げられます。
- 病気の有無・陽性陰性の判定
- スパムメールフィルタ
- ニュース記事の自動的カテゴリ振り分け
- 農作物の仕分け
- 推薦・レコメンドシステム
《機械学習の活用例3》異常検知
センサー等の測定データから、モデルの学習に効果的な特徴量を抽出し、それに基づいて異常や故障を検知します。
異常検知システムは工場の製造ラインや常時モニタリングを必要とするデータセンターなどで活躍しています。
一方で、機械学習は決して最近作り上げた学問ではなく、その理論は、統計学に基づいた従来の分析手法の延長上に発展してきました。
では、なぜ機械学習は近年注目を急激に集めるようになったのでしょうか?その背景にある要素の1つとしては、図6にあるような3つ要素です。
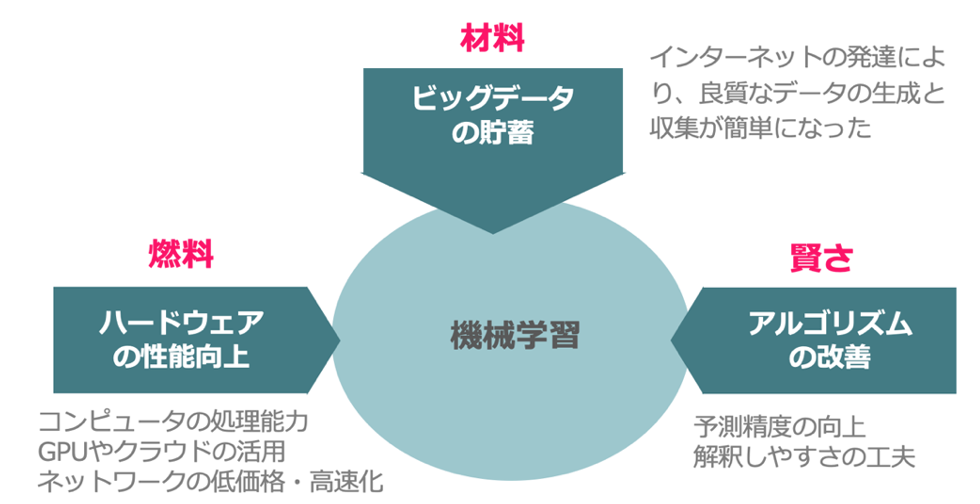
実はもう1つの要素があります。
機械学習モデルは、Pythonで実装されることが殆どからです。
Pythonはオープンソース(= 無償で利用可能)のプログラミング言語であり、かつ文法が非常にシンプルでどなたでも習いやすく使いやすいです。
さらに、Pythonにはデータ分析、機械学習に特化した専門性の高いライブラリやソフトウェアツールがたくさん揃っています。
Pythonのライブラリを活用すると、長年かけて機械学習のアルゴリズムや複雑なコーディングを習得しようよしなくても、機械学習を手軽に活用可能になれます。
AI・データサイエンス、機械学習の
実践力を高めたい方へ
- プログラミングを0から学びたい
- データサイエンティスト、データアナリストを目指したい
- AIエンジニア、大規模言語モデル(LLM)エンジニアを目指したい
AI人材コースを
無料体験してみませんか?
フリープラン登録で無料で120以上の教材を学び放題!
生成AIを使うだけでなくAIの本質を理解し課題解決力を習得!
重要箇所のハイライトと進捗の可視化で効率的な学習サポート!
1分で簡単!無料!
▶アカウント作成して無料体験する
30時間以上の動画講座が見放題!
追加購入不要!これだけで学習できるカリキュラム
(質問制度や添削プラン等)充実したサポート体制!
▶AI人材コースを見る



